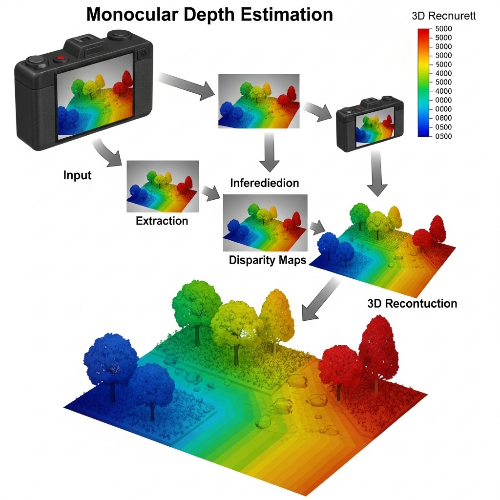
서론: 3D Depth Estimation의 중요성
3D Depth Estimation, 즉 3D 깊이 추정은 단일 이미지 또는 여러 이미지를 통해 장면 내 각 픽셀의 깊이 정보(카메라로부터의 거리)를 추론하는 기술입니다. 이는 이미지 처리 및 컴퓨터 비전 분야에서 가장 핵심적이고 도전적인 연구 분야 중 하나로 손꼽힙니다. 자율주행, 로봇 공학, 가상/증강 현실(VR/AR), 3D 모델링, 그리고 의료 영상 분석 등 수많은 첨단 기술 분야에서 3D 깊이 정보는 필수적인 역할을 수행합니다. 특히, 단안 카메라(Monocular Camera)를 이용한 깊이 추정은 비용 효율성과 시스템 단순성이라는 장점으로 인해 큰 주목을 받고 있습니다. 스테레오 카메라나 LiDAR와 같은 고가의 센서 없이도 3D 환경을 이해할 수 있게 해주는 이 기술은 센서 제약이 있는 환경에서도 유용하게 활용될 수 있습니다. 본 글에서는 단안 카메라 기반 깊이 추정 기법의 원리와 주요 모델, 그리고 응용 분야 및 한계점에 대해 심층적으로 다루고자 합니다.
단안 깊이 추정의 원리 및 도전 과제
단안 카메라를 이용한 깊이 추정은 2D 이미지에서 3D 정보를 복원하는 본질적으로 "불가능한" 문제로 여겨집니다. 단일 2D 이미지에는 깊이 정보가 직접적으로 포함되어 있지 않기 때문입니다. 사람의 시각 시스템은 양안 시차(Binocular Disparity)를 통해 깊이를 인지하지만, 단안 이미지는 이러한 직접적인 단서를 제공하지 않습니다. 따라서, 단안 깊이 추정은 주로 이미지 내의 다양한 시각적 단서(Visual Cues)에 의존합니다.
주요 시각적 단서들은 다음과 같습니다:
- 원근법(Perspective): 멀리 있는 객체는 이미지 평면에서 더 작게 보입니다.
- 텍스처 밀도(Texture Density): 동일한 텍스처라도 멀리 있을수록 더 조밀하게 보입니다.
- 가려짐(Occlusion): 가까운 객체가 멀리 있는 객체를 가립니다.
- 음영 및 조명(Shading and Lighting): 빛의 방향과 그림자를 통해 객체의 3D 형태를 유추할 수 있습니다.
- 초점 흐림(Defocus Blur): 카메라 초점에서 벗어난 객체는 흐릿하게 나타나며, 이 흐림 정도를 통해 깊이를 추정할 수 있습니다.
- 사전 지식(Prior Knowledge): 예를 들어, 자동차의 평균 크기나 사람이 서 있는 높이와 같은 일반적인 객체의 크기 정보를 활용할 수 있습니다.
이러한 단서들은 복합적으로 작용하여 깊이 정보를 유추하는 데 사용되지만, 단일 단서만으로는 정확한 깊이 추정이 어렵습니다. 또한, 카메라 시점 변화, 조명 조건 변화, 객체의 다양성 등 실제 환경의 복잡성은 단안 깊이 추정의 정확도를 떨어뜨리는 주요 도전 과제입니다.
딥러닝 기반 단안 깊이 추정
최근 딥러닝 기술의 발전은 단안 깊이 추정 분야에 혁신적인 변화를 가져왔습니다. 특히, 컨볼루션 신경망(CNN)은 이미지에서 복잡한 시각적 특징을 학습하고 이를 통해 깊이 맵을 예측하는 데 뛰어난 성능을 보였습니다. 딥러닝 기반 접근 방식은 크게 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)으로 나눌 수 있습니다.
1. 지도 학습 기반 깊이 추정
지도 학습은 실제 깊이 값(Ground Truth Depth)이 있는 데이터셋을 사용하여 모델을 학습시키는 방식입니다. LiDAR 센서나 스테레오 카메라 등을 통해 정밀하게 측정된 깊이 맵을 정답 데이터로 활용합니다.
- 모델 구조: 대부분 인코더-디코더(Encoder-Decoder) 구조를 기반으로 합니다. 인코더는 입력 이미지에서 고수준 특징을 추출하고, 디코더는 이 특징들로부터 깊이 맵을 재구성합니다. U-Net, ResNet, VGG 등의 백본 네트워크가 주로 사용됩니다.
- 손실 함수: 예측된 깊이 맵과 실제 깊이 맵 간의 차이를 최소화하는 방향으로 학습이 이루어집니다. MSE(Mean Squared Error), MAE(Mean Absolute Error)와 같은 L1/L2 손실 외에도, 구조적 유사성을 고려하는 SSIM(Structural Similarity Index Measure) 손실이나 경계선 보존을 위한 그라디언트 손실 등이 함께 사용됩니다.
- 장점: 정확도가 높고 안정적인 깊이 추정 성능을 기대할 수 있습니다.
- 단점: 고품질의 정답 깊이 데이터셋 구축이 매우 어렵고 비용이 많이 든다는 점이 가장 큰 한계입니다. 이는 특히 실제 환경에서 대규모 데이터를 확보하는 데 큰 걸림돌이 됩니다.
2. 비지도 학습 및 자기 지도 학습 기반 깊이 추정
지도 학습의 데이터셋 구축 어려움을 극복하기 위해 제안된 것이 비지도 학습(Unsupervised Learning) 또는 자기 지도 학습(Self-Supervised Learning) 방식입니다. 이 방식은 깊이 정답 데이터 없이 연속된 비디오 프레임이나 스테레오 이미지 쌍을 활용하여 모델을 학습시킵니다.
- 기본 원리: 비디오 프레임 간의 기하학적 일관성(Geometric Consistency)을 활용합니다. 즉, 한 시점에서 다른 시점으로 카메라가 이동했을 때, 깊이 정보와 카메라의 움직임(Pose)을 알면 원래 이미지를 재구성할 수 있다는 원리를 이용합니다. 모델은 깊이 맵과 카메라 포즈를 동시에 예측하도록 학습되며, 재구성된 이미지와 원본 이미지 간의 차이를 최소화하는 방식으로 최적화됩니다.
- 주요 접근 방식:
- View Synthesis Loss (뷰 합성 손실): 가장 널리 사용되는 방법으로, 현재 프레임에서 예측된 깊이 맵과 다음 프레임으로의 카메라 이동을 사용하여 다음 프레임을 "합성"합니다. 합성된 프레임과 실제 다음 프레임 간의 차이(픽셀 단위의 재구성 오차)를 손실 함수로 사용합니다.
- Epipolar Geometry Constraint (에피폴라 기하 제약): 스테레오 이미지 쌍을 활용하는 경우, 두 카메라 간의 에피폴라 기하학적 관계를 이용하여 깊이와 포즈를 추정합니다.
- Masking/Occlusion Handling: 비디오 프레임 간 객체 이동이나 가려짐으로 인해 발생하는 재구성 오차를 줄이기 위해 마스킹 기법이나 동적 객체 처리 기법이 추가됩니다.
- 장점: 대규모의 레이블링 되지 않은 비디오 데이터를 활용할 수 있어 데이터 구축 비용이 매우 낮습니다. 실제 환경 데이터로 학습할 수 있어 일반화 성능이 뛰어날 수 있습니다.
- 단점: 지도 학습 방식에 비해 정확도가 다소 떨어질 수 있으며, 복잡한 장면이나 빠르게 움직이는 객체에 대한 처리 성능이 불안정할 수 있습니다.
3. 기타 딥러닝 기반 모델
- MegaDepth: 대규모 인터넷 이미지와 SfM(Structure from Motion) 데이터를 활용하여 깊이 맵을 추정하는 모델로, 다양한 환경에 대한 일반화 성능을 높였습니다.
- Monodepth2: 자기 지도 학습 기반의 대표적인 모델로, 뷰 합성 손실에 스무딩 손실, 자동 마스킹 등의 기법을 추가하여 성능을 크게 향상시켰습니다.
- AdaBins: 어텐션 메커니즘을 활용하여 픽셀의 깊이 분포를 예측하고 이를 기반으로 정확한 깊이 맵을 생성하는 모델입니다.
응용 분야
단안 카메라 기반 3D Depth Estimation은 다양한 산업 및 연구 분야에서 혁신적인 가능성을 열어주고 있습니다.
- 자율주행: 주변 환경의 3D 구조를 이해하고, 도로, 차량, 보행자 등 객체와의 거리를 정확히 파악하여 안전한 경로 계획 및 충돌 회피에 필수적으로 사용됩니다.
- 로봇 공학: 로봇이 주변 환경을 인식하고, 객체의 위치를 파악하여 효과적인 조작 및 내비게이션을 수행하는 데 기여합니다.
- 증강 현실(AR) / 가상 현실(VR): 실제 공간의 깊이 정보를 활용하여 가상 객체를 현실 공간에 자연스럽게 배치하고, 현실 객체와의 상호작용 및 가려짐 효과를 구현하는 데 핵심적인 역할을 합니다.
- 3D 모델링 및 재구성: 단일 이미지를 기반으로 3D 모델을 생성하거나, 여러 이미지를 통해 복잡한 장면의 3D 재구성을 수행하여 건축, 문화유산 보존, 게임 개발 등에 활용됩니다.
- 의료 영상 분석: CT, MRI 등 2D 의료 영상에서 3D 정보를 추출하여 질병 진단, 수술 계획 수립, 장기 모델링 등에 도움을 줍니다.
- 보안 및 감시: CCTV 영상에서 사람이나 객체의 깊이를 추정하여 이상 행동 감지, 침입자 식별 등의 지능형 감시 시스템을 구축할 수 있습니다.
- 농업 및 환경 모니터링: 드론이나 지상 로봇에 장착된 카메라를 통해 작물의 성장 깊이, 지형 고도 등을 파악하여 정밀 농업에 기여합니다.
한계점 및 향후 발전 방향
단안 카메라 기반 깊이 추정 기술은 상당한 발전을 이루었지만, 여전히 몇 가지 한계점을 가지고 있습니다.
- 정확도 및 정밀도: LiDAR나 스테레오 카메라에 비해 여전히 깊이 추정의 절대적인 정확도와 정밀도가 떨어집니다. 특히, 반사율이 낮은 객체, 투명한 객체, 텍스처가 부족한 영역에서는 성능이 저하될 수 있습니다.
- 규모 모호성(Scale Ambiguity): 단안 이미지는 절대적인 깊이 정보를 직접적으로 제공하지 않기 때문에, 추정된 깊이 맵이 실제 스케일에 비해 확대되거나 축소되는 스케일 모호성 문제가 발생할 수 있습니다. 이를 해결하기 위해 객체의 사전 지식이나 IMU(관성 측정 장치) 등 다른 센서와의 융합이 필요합니다.
- 일반화 성능: 학습 데이터의 분포에 크게 의존하기 때문에, 학습 환경과 다른 새로운 환경에서는 성능 저하가 발생할 수 있습니다.
- 실시간 처리: 고해상도 이미지에 대해 정확한 깊이 맵을 추정하는 것은 여전히 상당한 연산량을 요구하여 실시간 응용에 제약이 있을 수 있습니다.
향후 단안 깊이 추정 기술은 다음과 같은 방향으로 발전할 것으로 예상됩니다.
- 멀티모달 센서 융합: IMU, GPS, 레이더 등 다른 센서 데이터와의 융합을 통해 깊이 추정의 정확도와 강건성을 높이는 연구가 활발히 진행될 것입니다.
- 강화 학습 및 메타 학습: 더욱 복잡하고 다양한 환경에 대한 일반화 성능을 향상시키기 위해 강화 학습이나 메타 학습 기법이 도입될 수 있습니다.
- 경량화 및 효율성: 임베디드 시스템이나 모바일 기기에서의 실시간 처리를 위해 모델의 경량화 및 효율적인 연산 기법 개발이 중요해질 것입니다.
- 동적 환경 처리: 움직이는 객체나 복잡한 상호작용이 있는 동적 환경에서의 깊이 추정 성능을 향상시키는 연구가 지속될 것입니다.
- 새로운 벤치마크 및 데이터셋: 실제 환경의 복잡성을 반영하고, 다양한 시나리오를 포함하는 대규모의 고품질 데이터셋 및 벤치마크가 지속적으로 구축될 것입니다.
결론
단안 카메라를 통한 3D Depth Estimation은 컴퓨터 비전 분야의 가장 흥미롭고 실용적인 연구 주제 중 하나입니다. 딥러닝 기술의 발전에 힘입어 단일 2D 이미지에서 3D 공간 정보를 유추하는 능력이 비약적으로 발전했으며, 이는 자율주행, 로봇, AR/VR 등 다양한 첨단 기술의 핵심 동력으로 작용하고 있습니다. 비록 아직 해결해야 할 과제들이 남아있지만, 지속적인 연구와 기술 혁신을 통해 단안 깊이 추정 기술은 더욱 정교하고 강건해질 것이며, 우리 삶의 다양한 영역에서 새로운 가치를 창출할 것으로 기대됩니다.
'컴퓨터 비전 & AI > 구조 기반 탐색 및 이해' 카테고리의 다른 글
| Geometry‑based SLAM과 컴퓨터 비전 연계 탐사 로봇 설계 (2) | 2025.06.26 |
|---|---|
| Active Vision 시스템: 능동적 이미지 인식 알고리즘 최신 기법 (0) | 2025.06.26 |
| Stereo Vision을 활용한 몰입형 AR 콘텐츠 생성 방법 (0) | 2025.06.25 |
| OpenCV + 딥러닝 기반의 영역 분할(Segmentation) 기술 심층 분석 (0) | 2025.06.24 |
| Edge & Contour Detection을 넘어선 실시간 경계 인식 기술 (1) | 2025.06.24 |



