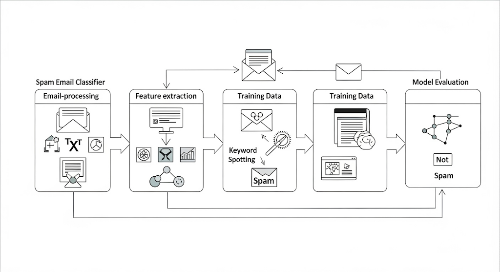
스팸 필터링의 중요성과 배경
이메일은 오늘날 가장 널리 사용되는 디지털 커뮤니케이션 수단 중 하나입니다. 하지만 스팸 이메일은 사용자의 시간을 낭비하고, 피싱이나 악성코드 전파의 통로가 되기도 합니다. 기업과 개인 모두에게 스팸 필터는 보안과 생산성의 핵심 도구입니다. 이러한 스팸 이메일을 효율적으로 분류하기 위해 머신러닝 기반의 분류기를 구축하는 것이 오늘날의 트렌드입니다.
머신러닝을 활용하면 기존의 키워드 필터 방식보다 훨씬 유연하고 정확한 스팸 탐지가 가능합니다. 본 글에서는 머신러닝을 이용해 실제로 스팸 이메일 분류기를 구축하는 과정을 단계별로 설명합니다.
스팸 이메일 분류기의 개념
스팸 이메일 분류기는 이메일의 내용을 분석하여 이를 ‘스팸(Spam)’ 혹은 ‘정상(Ham)’으로 자동 분류하는 시스템입니다. 이때 머신러닝 모델은 대량의 학습 데이터를 기반으로 텍스트의 패턴을 학습하고, 이를 바탕으로 새로운 이메일의 유형을 예측합니다.
모델은 통계적인 특성과 단어의 빈도, 문맥 등을 학습하여 스팸을 구분하며, 이를 통해 높은 정확도의 자동화된 이메일 필터링이 가능합니다.
데이터 수집 및 전처리
1. 데이터셋 선택
대표적으로 사용되는 스팸 필터링용 공개 데이터셋은 다음과 같습니다:
- SMS Spam Collection
- Enron Spam Dataset
- SpamAssassin Public Corpus
이러한 데이터셋은 이미 라벨이 부착된 상태로, ‘spam’ 또는 ‘ham’이라는 태그가 각 메시지에 포함되어 있어 학습에 적합합니다.
2. 텍스트 정제
텍스트 데이터는 머신러닝 모델이 직접 처리하기 어려우므로, 먼저 전처리가 필요합니다. 일반적으로 다음과 같은 단계가 포함됩니다:
- 소문자 변환
- 특수 문자 제거
- 불용어(stopwords) 제거
- 어간 추출(stemming) 또는 표제어 추출(lemmatization)
전처리 과정을 통해 의미 없는 정보는 제거되고, 핵심 정보만이 남아 모델의 학습 효율이 높아집니다.
피처 벡터화: 텍스트를 숫자로 변환
텍스트 데이터를 머신러닝 모델에 적용하려면 벡터 형태로 변환해야 합니다. 대표적인 벡터화 기법은 다음과 같습니다:
- Bag of Words (BoW): 단어의 등장 빈도만을 고려하는 가장 기본적인 방법입니다.
- TF-IDF (Term Frequency – Inverse Document Frequency): 단어의 빈도뿐 아니라 문서 전체에서의 중요도를 반영합니다.
- Word Embedding (Word2Vec, GloVe): 문맥 정보를 반영해 단어를 고차원 벡터로 표현합니다.
스팸 분류기의 경우 BoW나 TF-IDF만으로도 충분히 우수한 성능을 낼 수 있습니다.
머신러닝 모델 선택
스팸 분류기에 적합한 대표적인 머신러닝 알고리즘은 다음과 같습니다:
1. 나이브 베이즈(Naive Bayes)
텍스트 분류에 자주 사용되는 알고리즘으로, 단어들의 독립성을 가정하고 확률 기반으로 스팸 여부를 판단합니다. 학습 속도와 예측 속도가 빠르며, 성능도 매우 우수합니다.
2. 로지스틱 회귀(Logistic Regression)
선형 모델로서, BoW 또는 TF-IDF 벡터와 잘 결합되어 높은 정확도를 보입니다.
3. 서포트 벡터 머신(SVM)
고차원 벡터 공간에서 경계를 찾아 분류하는 알고리즘으로, 작은 데이터셋에서 특히 효과적입니다.
4. 딥러닝 기반 모델
LSTM, GRU 같은 순환 신경망(RNN)이나 Transformer 계열 모델은 대용량 데이터에서 뛰어난 성능을 보이나, 리소스가 더 많이 필요합니다.
학습, 검증 및 성능 평가
1. 학습과 검증
데이터셋을 훈련 데이터와 테스트 데이터로 나눈 뒤, 학습된 모델의 성능을 평가합니다. 일반적으로 80:20 또는 70:30 비율로 데이터를 분리합니다.
2. 평가 지표
- 정확도(Accuracy): 전체 예측 중 맞춘 비율
- 정밀도(Precision): 스팸으로 분류된 것 중 실제 스팸 비율
- 재현율(Recall): 실제 스팸 중 맞게 분류한 비율
- F1 Score: 정밀도와 재현율의 조화 평균
스팸 분류에서는 F1 Score가 가장 중요한 지표로 여겨집니다. 이는 데이터가 불균형한 경우(스팸이 전체의 10% 등) 정밀도와 재현율 간의 균형을 보여주기 때문입니다.
모델 개선 전략
1. 하이퍼파라미터 튜닝
그리드 서치(Grid Search)나 랜덤 서치(Random Search)를 통해 모델의 파라미터를 최적화하여 성능을 향상시킬 수 있습니다.
2. 앙상블 기법
랜덤 포레스트(Random Forest), 그래디언트 부스팅(Gradient Boosting) 등 앙상블 기법을 사용하면 여러 모델의 결과를 조합해 더 나은 성능을 얻을 수 있습니다.
3. 실시간 업데이트
스팸의 유형은 계속 진화하므로, 분류기도 지속적인 학습과 업데이트가 필요합니다. 스트리밍 데이터 기반 학습 또는 주기적인 재학습이 효과적입니다.
실제 환경에서의 적용 시 고려사항
- 피싱 이메일 탐지: 스팸 분류기를 확장하면 피싱 공격 탐지도 가능해집니다.
- 다국어 지원: 다양한 언어에서의 스팸 탐지 능력을 고려해야 하며, 이를 위해 멀티랭귀지 모델이 필요합니다.
- 성능과 속도 균형: 이메일 필터링은 실시간 처리 속도가 중요하므로, 가벼운 모델을 사용하거나 API 캐싱 등을 적용할 수 있습니다.
결론: 사용자 경험과 보안을 모두 고려한 AI 활용
스팸 이메일 분류기는 AI 기술이 실제로 우리의 일상에 유용하게 적용되는 대표 사례 중 하나입니다. 간단한 규칙 기반에서 시작된 필터링은 이제 머신러닝과 자연어 처리 기술을 바탕으로 정교하게 발전하고 있습니다. 앞으로는 더 많은 기업과 개인 사용자들이 이러한 AI 기반 분류 시스템을 손쉽게 활용할 수 있게 될 것입니다.
'컴퓨터 비전 & AI' 카테고리의 다른 글
| 주식 가격 예측 모델 개발: 인공지능과 데이터 과학의 만남 (4) | 2025.06.21 |
|---|---|
| 영화 추천 시스템 만들기: 맞춤형 콘텐츠 추천의 핵심 기술 (2) | 2025.06.20 |
| 챗봇 개발: FAQ 자동 응답 시스템의 원리와 구현 방법 (0) | 2025.06.19 |
| 이미지 분류기 개발: 고양이 vs 개 (2) | 2025.06.19 |
| 자연어 처리 프로젝트: 뉴스 기사 분류 (0) | 2025.06.18 |



