이미지 기반 인공지능의 핵심, 분류와 탐지
딥러닝이 다양한 산업 분야에 확산되면서 이미지 기반 인공지능 기술도 빠르게 발전하고 있습니다. 이 중 가장 기본이 되는 두 가지 기술이 바로 **이미지 분류(Image Classification)**와 **객체 탐지(Object Detection)**입니다. 이 두 기술은 모두 컴퓨터가 이미지를 이해하고 인식하도록 하는 데 사용되지만, 목표와 처리 방식, 출력 결과가 본질적으로 다릅니다.
본 글에서는 이미지 분류와 객체 탐지의 개념, 작동 원리, 주요 알고리즘, 활용 사례 등을 비교하며 상세히 알아보겠습니다.
이미지 분류(Image Classification)란?
이미지 분류의 정의
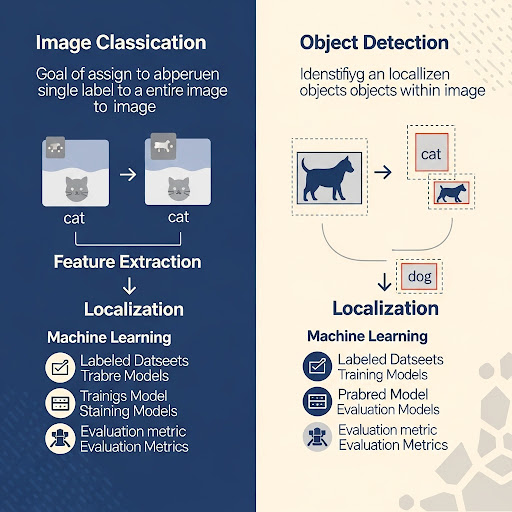
이미지 분류는 컴퓨터가 하나의 이미지를 보고, 그 이미지가 어떤 카테고리에 속하는지 판별하는 작업입니다. 예를 들어, 고양이와 개를 구분하거나, 정상 조직과 종양 조직을 분류하는 의료 영상 분석에 활용됩니다.
작동 원리
이미지 분류는 일반적으로 다음과 같은 순서로 이루어집니다:
- 입력 이미지 전처리: 이미지 크기를 조정하고 픽셀 값을 정규화합니다.
- 특징 추출: 합성곱 신경망(CNN)을 통해 이미지의 시각적 특징을 추출합니다.
- 분류기 적용: 추출된 특징을 기반으로 Fully Connected Layer에서 Softmax 함수 등을 통해 각 클래스에 대한 확률을 계산합니다.
- 결과 출력: 가장 높은 확률을 가진 클래스가 최종 예측 결과로 선택됩니다.
대표 모델
- LeNet-5: 초창기 손글씨 숫자 분류용 모델.
- AlexNet: 대규모 이미지넷 챌린지에서 딥러닝의 가능성을 입증한 모델.
- VGGNet, ResNet, EfficientNet 등: 성능 향상을 위해 더 깊고 복잡한 구조를 도입한 최신 모델들.
객체 탐지(Object Detection)란?
객체 탐지의 정의
객체 탐지는 단순히 이미지 안에 무엇이 있는지를 분류하는 것을 넘어, 여러 개의 객체를 식별하고, 각 객체의 위치(좌표)를 지정하는 작업입니다. 예를 들어, 한 이미지에서 자동차, 보행자, 신호등을 각각 탐지하고 위치를 박스로 표시하는 것입니다.
작동 원리
객체 탐지는 이미지 분류보다 더 복잡한 구조를 필요로 하며 다음과 같은 절차를 따릅니다:
- 이미지 입력 및 전처리
- 특징 맵 생성: CNN을 이용해 이미지로부터 특징 맵을 추출.
- 경계 상자(Bounding Box) 예측: 이미지 내 여러 위치에서 객체 후보 영역을 예측.
- 클래스 분류 및 위치 조정: 각 박스 내 객체의 클래스와 정확한 위치를 계산.
- 비최대 억제(NMS): 중복된 박스를 제거하고 최종 탐지 결과를 결정.
대표 알고리즘
- R-CNN 계열: R-CNN → Fast R-CNN → Faster R-CNN으로 발전하며 처리 속도와 정확도 향상.
- YOLO(You Only Look Once): 실시간 객체 탐지에 최적화된 모델. 한 번의 네트워크 통과로 모든 객체 예측.
- SSD(Single Shot MultiBox Detector): 다양한 크기의 객체를 동시에 탐지할 수 있는 경량화 모델.
이미지 분류와 객체 탐지의 차이점
| 요소 | 이미지 분류 | 객체 탐지 |
| 목표 | 이미지 전체를 하나의 클래스로 분류 | 이미지 내 객체들을 구분하고 위치를 표시 |
| 출력 | 단일 클래스 라벨 | 여러 클래스와 객체 위치(좌표) |
| 복잡도 | 상대적으로 낮음 | 상대적으로 높음 |
| 활용 예시 | 이미지 필터링, 의료 진단, 제품 분류 | 자율주행, 보안 감시, 얼굴 인식 |
※ 표는 설명을 위해 글로 구성되었습니다.
이미지 분류의 주요 활용 사례
1. 의료 영상 진단
의사들이 확인해야 할 MRI, CT 이미지 등을 분류하여 암, 폐렴, 뇌졸중 여부 등을 빠르게 파악할 수 있습니다.
2. 상품 이미지 태깅
전자상거래 플랫폼에서 상품 이미지에 자동으로 ‘의류’, ‘신발’, ‘전자기기’ 등 라벨을 붙이는 데 사용됩니다.
3. 위성 이미지 분석
위성 사진을 분석해 도시, 숲, 바다 등의 지형을 분류하여 지도 생성 및 환경 모니터링에 활용됩니다.
객체 탐지의 주요 활용 사례
1. 자율주행 시스템
차량 주변의 차량, 보행자, 장애물 등을 탐지해 주행 경로를 결정하고 충돌을 방지합니다.
2. 보안 감시 및 얼굴 인식
CCTV 영상에서 사람을 탐지하고 이상 행동을 감지하거나, 얼굴을 인식하여 출입을 제어합니다.
3. 산업용 검사 시스템
생산 라인에서 제품의 결함이나 이상 요소를 자동으로 감지해 품질 검사를 수행합니다.
두 기술의 융합과 딥러닝의 발전
현대 딥러닝 기술은 이미지 분류와 객체 탐지를 동시에 수행할 수 있는 **멀티태스크 모델(Multi-task Model)**로 발전하고 있습니다. 예를 들어, YOLOv8이나 EfficientDet은 정밀도와 처리 속도 사이의 균형을 유지하며 복잡한 장면에서도 빠르고 정확하게 객체를 탐지합니다.
또한 Transformer 기반의 Vision Transformer(ViT) 모델이 등장하면서 기존 CNN 기반 모델을 대체할 가능성도 논의되고 있습니다. 이로 인해 이미지 처리 분야는 더 넓고 정교한 응용이 가능해졌습니다.
결론: 기술 선택의 기준은 목적에 달려 있다
이미지 분류와 객체 탐지는 목적과 상황에 따라 선택해야 합니다. 단일 이미지의 속성을 파악하고자 한다면 이미지 분류가 적합하고, 이미지나 영상에서 다수의 객체를 인식하고 위치까지 파악하려면 객체 탐지가 필요합니다.
최근에는 이 두 기술이 통합된 형태로 응용되는 경우도 많으며, 인공지능이 시각적 인식을 필요로 하는 거의 모든 분야에서 이 기술들이 핵심 역할을 하고 있습니다.
'컴퓨터 비전 & AI' 카테고리의 다른 글
| 이미지 세분화(Segmentation)의 기법과 활용 (2) | 2025.05.25 |
|---|---|
| YOLO와 SSD: 실시간 객체 탐지 모델 비교 (1) | 2025.05.25 |
| 컴퓨터 비전이란? 기본 개념과 응용 분야 (2) | 2025.05.24 |
| 가상화 기술의 종류와 비교: VM vs. 컨테이너 (0) | 2025.05.08 |
| 시스템 로그 분석을 통한 문제 해결 방법 (1) | 2025.05.08 |



