Contrastive Learning: SimCLR, MoCo를 활용한 이미지 표현 학습
개요
Contrastive Learning은 현대 Self-Supervised Learning 분야에서 가장 효과적인 학습 방법론 중 하나로 자리잡았습니다. 레이블이 없는 이미지 데이터로부터 의미있는 표현을 학습하는 이 기법은 SimCLR과 MoCo 같은 혁신적인 모델들을 통해 지도학습에 필적하는 성능을 달성하고 있습니다.
Contrastive Learning의 핵심 원리
기본 학습 메커니즘
Contrastive Learning의 핵심 아이디어는 매우 직관적입니다. 유사한 데이터 포인트들은 표현 공간에서 가깝게, 다른 데이터 포인트들은 멀리 배치하는 것입니다. 이를 통해 모델은 데이터의 본질적인 특성을 파악하고 의미있는 표현을 학습하게 됩니다.
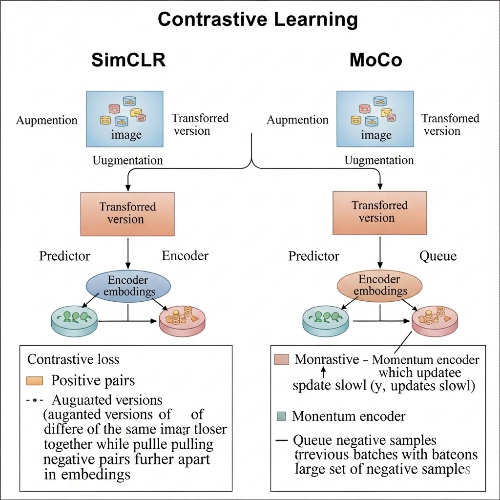
구체적으로, 하나의 이미지에서 서로 다른 augmentation을 적용한 두 view를 positive pair로 정의하고, 다른 이미지들을 negative pair로 구성합니다. 모델은 positive pair 간의 거리는 최소화하고, negative pair 간의 거리는 최대화하는 방향으로 학습됩니다.
Data Augmentation의 중요성
Contrastive Learning에서 data augmentation은 단순한 전처리 기법이 아닌 핵심 구성 요소입니다. 동일한 이미지에 대해 다양한 변형을 적용하여 positive pair를 생성하는데, 이때 사용되는 augmentation 기법들은 색상 변환, 회전, 크롭핑, 가우시안 블러 등이 있습니다.
효과적인 augmentation은 모델이 invariant한 특성을 학습하도록 도와줍니다. 예를 들어, 색상 변환을 통해 모델은 객체의 형태와 구조에 더 집중하게 되고, 크롭핑을 통해 부분적인 정보만으로도 전체를 이해할 수 있는 능력을 기릅니다.
SimCLR: 단순함의 힘
아키텍처와 학습 과정
SimCLR(A Simple Framework for Contrastive Learning of Visual Representations)는 Google Research에서 제안한 방법으로, 그 이름에서 알 수 있듯이 단순하면서도 효과적인 접근법을 사용합니다.
SimCLR의 학습 과정은 다음과 같습니다. 먼저 미니배치 내의 각 이미지에 대해 두 개의 서로 다른 augmentation을 적용합니다. 이렇게 생성된 2N개의 이미지는 encoder를 거쳐 representation으로 변환되고, 이후 projection head를 통해 최종 feature로 변환됩니다.
NT-Xent(Normalized Temperature-scaled Cross Entropy) loss를 사용하여 같은 원본 이미지에서 생성된 두 view는 가깝게, 다른 이미지들과는 멀게 배치되도록 학습합니다. 이때 temperature parameter는 contrastive loss의 집중도를 조절하는 중요한 하이퍼파라미터입니다.
핵심 기술적 혁신
SimCLR의 성공 요인 중 하나는 projection head의 도입입니다. 이는 representation과 contrastive loss 사이에 위치하는 MLP 레이어로, downstream task에서는 사용되지 않지만 contrastive learning 과정에서는 성능 향상에 크게 기여합니다.
또한 대규모 배치 사이즈의 중요성을 입증했습니다. 더 큰 배치 사이즈는 더 많은 negative sample을 제공하여 더 안정적이고 효과적인 학습을 가능하게 합니다. 이를 위해 분산 학습과 gradient accumulation 기법들이 활용됩니다.
MoCo: 메모리 효율적 접근법
Momentum 기반 학습
MoCo(Momentum Contrast)는 Facebook AI Research에서 제안한 방법으로, 메모리 효율성과 학습 안정성을 동시에 해결한 혁신적인 접근법입니다.
MoCo의 핵심 아이디어는 momentum을 활용한 key encoder의 업데이트입니다. Query encoder는 일반적인 gradient descent로 업데이트되지만, key encoder는 momentum을 사용하여 더 천천히 업데이트됩니다. 이를 통해 key들 간의 일관성을 유지하면서도 안정적인 학습이 가능합니다.
Memory Queue 시스템
MoCo의 또 다른 혁신은 memory queue 시스템입니다. 이 시스템은 이전 배치들의 key들을 저장하여 현재 배치의 query와 대조할 수 있도록 합니다. 이를 통해 큰 배치 사이즈 없이도 충분한 수의 negative sample을 확보할 수 있습니다.
Queue는 FIFO(First In, First Out) 방식으로 동작하며, 새로운 key가 들어오면 가장 오래된 key가 제거됩니다. 이 과정에서 gradient는 queue에 저장된 key들로 전파되지 않아 메모리 효율성을 유지할 수 있습니다.
실제 성능과 응용 분야
ImageNet 벤치마크 성과
SimCLR과 MoCo는 ImageNet 분류 작업에서 놀라운 성과를 보여주었습니다. 특히 SimCLR은 ResNet-50 아키텍처를 사용하여 top-1 accuracy 69.3%를 달성했으며, 이는 당시 supervised learning 대비 7% 차이에 불과한 결과였습니다.
MoCo v2는 SimCLR의 일부 기법들을 도입하여 성능을 더욱 향상시켰고, 특히 적은 계산 자원으로도 우수한 성능을 달성할 수 있음을 보여주었습니다.
Transfer Learning 효과
Contrastive Learning으로 사전 학습된 모델들은 다양한 downstream task에서 뛰어난 transfer learning 성능을 보입니다. Object detection, semantic segmentation, instance segmentation 등의 작업에서 supervised pre-training을 능가하는 경우도 많습니다.
특히 제한된 라벨 데이터만 있는 few-shot learning 상황에서 그 효과가 더욱 두드러집니다. 풍부한 unlabeled 데이터로부터 학습한 표현은 새로운 도메인에서도 빠르게 적응할 수 있는 능력을 보여줍니다.
기술적 발전과 최적화 전략
하이퍼파라미터 최적화
Contrastive Learning의 성능은 여러 하이퍼파라미터에 민감하게 반응합니다. Temperature parameter, learning rate, momentum coefficient, queue size 등의 적절한 설정이 성공적인 학습의 핵심입니다.
특히 temperature parameter는 contrastive loss의 집중도를 조절하는 중요한 요소로, 너무 높으면 학습이 어려워지고 너무 낮으면 hard negative에 과도하게 집중할 수 있습니다.
계산 효율성 개선
대규모 Contrastive Learning을 위해서는 효율적인 계산 전략이 필요합니다. Gradient checkpointing, mixed precision training, 그리고 효율적인 negative sampling 기법들이 실제 구현에서 중요한 역할을 합니다.
또한 distributed training을 통해 여러 GPU에서 동시에 학습을 수행하는 것이 일반적이며, 이때 batch normalization과 같은 기법들의 처리 방식도 중요한 고려사항입니다.
미래 전망과 발전 방향
멀티모달 확장
최근 연구들은 Contrastive Learning을 이미지뿐만 아니라 텍스트, 오디오 등 다양한 모달리티로 확장하고 있습니다. CLIP과 같은 모델들은 이미지와 텍스트 간의 contrastive learning을 통해 강력한 멀티모달 표현을 학습합니다.
효율성과 확장성
향후 연구 방향 중 하나는 더 효율적인 negative sampling과 메모리 사용량 최적화입니다. 또한 더 큰 규모의 데이터셋과 모델에 대한 확장성도 중요한 과제입니다.
마무리
SimCLR과 MoCo로 대표되는 Contrastive Learning은 Self-Supervised Learning 분야에 혁명적인 변화를 가져왔습니다. 이들 방법론은 레이블이 없는 대량의 이미지 데이터로부터 의미있는 표현을 학습할 수 있는 효과적인 방법을 제시하며, 다양한 컴퓨터 비전 작업에서 그 효과를 입증했습니다. 앞으로도 이 분야의 지속적인 발전이 AI 기술의 실용화에 큰 기여를 할 것으로 기대됩니다.