Transformer 모델의 원리와 응용
🔍 서론: 딥러닝의 진화와 Transformer의 등장
자연어 처리(NLP)는 오랫동안 RNN(Recurrent Neural Networks)과 LSTM(Long Short-Term Memory) 같은 순차 모델에 의존해 왔습니다. 하지만 이러한 구조는 긴 문장 처리에 한계가 있었고, 병렬화가 어렵다는 문제점도 존재했습니다.
이러한 한계를 극복하기 위해 2017년 구글이 발표한 논문 **“Attention is All You Need”**에서 소개된 Transformer 모델은 자연어 처리 분야뿐 아니라 컴퓨터 비전, 음성 인식 등 다양한 인공지능 분야에서 혁신을 불러일으켰습니다. 지금 우리가 사용하는 BERT, GPT, T5, ViT 등 대부분의 최신 딥러닝 모델은 Transformer 구조를 기반으로 하고 있습니다.
⚙️ Transformer의 기본 구조
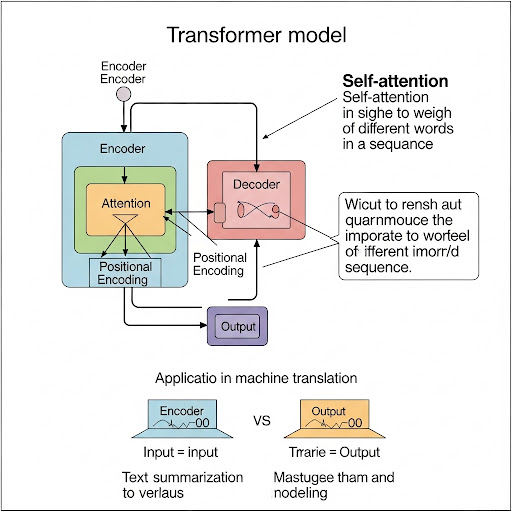
Transformer는 기존의 순차 모델과 달리 입력 데이터를 전체적으로 한 번에 처리하는 병렬적 구조를 채택합니다. 핵심 요소는 바로 Self-Attention 메커니즘과 포지셔널 인코딩, 그리고 인코더-디코더 아키텍처입니다.
✅ 인코더와 디코더
Transformer는 크게 두 부분으로 나뉩니다:
- 인코더(Encoder): 입력 문장을 받아 의미를 추출합니다.
- 디코더(Decoder): 인코더가 추출한 의미를 바탕으로 출력 문장을 생성합니다.
기계 번역에서는 예를 들어 영어 문장을 인코더가 처리하고, 디코더가 이를 한국어 문장으로 변환합니다.
✅ Self-Attention 메커니즘
Transformer의 핵심은 Self-Attention입니다. 이는 문장의 각 단어가 다른 단어들과 얼마나 관련 있는지를 계산하는 방식입니다. 이 메커니즘을 통해 모델은 문장 전체를 동시에 바라보며, 특정 단어가 어떤 문맥에서 사용되고 있는지를 파악할 수 있습니다.
예를 들어, “그녀는 사과를 먹었다. 그것은 빨갛고 달콤했다.”에서 “그것”이 무엇을 지칭하는지(사과)를 Self-Attention을 통해 모델이 정확히 이해할 수 있습니다.
✅ 포지셔널 인코딩(Positional Encoding)
Transformer는 순서를 고려하지 않는 구조이기 때문에, 각 단어의 위치 정보를 추가로 입력해줘야 합니다. 이를 포지셔널 인코딩이라고 하며, 사인(sin)과 코사인(cos) 함수 기반으로 각 위치를 고유하게 인코딩하여 입력에 더합니다.
🧠 Transformer의 학습 방식
Transformer는 입력 문장을 벡터로 변환하고, Attention을 통해 단어 간의 관계를 수치화합니다. 그런 다음 여러 층의 인코더와 디코더를 거치면서 문장의 의미를 더 깊이 이해하게 됩니다.
학습 시에는 병렬 처리 덕분에 GPU를 더 효율적으로 사용할 수 있어, 대규모 데이터셋을 빠르게 학습하는 데 유리합니다. 이러한 구조 덕분에 Transformer는 학습 속도와 정확도 측면에서 RNN 기반 모델보다 뛰어난 성능을 발휘합니다.
🌐 다양한 Transformer 기반 모델
Transformer는 원래 기계 번역을 위한 모델이었지만, 현재는 다양한 분야에서 응용되고 있습니다. 대표적인 Transformer 기반 모델은 다음과 같습니다.
✅ BERT (Bidirectional Encoder Representations from Transformers)
BERT는 Transformer의 인코더만 사용하여 문장의 양방향 문맥을 이해하는 데 탁월합니다. 검색, 감성 분석, 문장 분류 등 다양한 NLP 작업에 사용됩니다.
✅ GPT (Generative Pre-trained Transformer)
GPT는 Transformer의 디코더 구조를 사용하며, 언어 생성에 특화된 모델입니다. 챗봇, 문서 생성, 번역, 요약 등 다양한 생성형 AI 분야에 응용됩니다.
✅ T5 (Text-to-Text Transfer Transformer)
T5는 모든 NLP 문제를 텍스트 입력-출력 문제로 통합해 해결합니다. 예를 들어 번역, 질문 응답, 문장 분류 등을 하나의 프레임워크로 다룰 수 있습니다.
✅ Vision Transformer (ViT)
Transformer 구조는 텍스트뿐만 아니라 이미지 처리에도 활용됩니다. ViT는 이미지를 패치(patch) 단위로 나누어 입력받고, 이를 Attention을 통해 분석함으로써 기존 CNN 모델에 비해 경쟁력 있는 성능을 보여줍니다.
🛠️ 실제 응용 사례
Transformer는 이론적인 모델을 넘어 다양한 실제 서비스에 적용되고 있습니다.
🔎 1. 검색 엔진 개선
Google은 BERT를 검색 알고리즘에 적용하여 사용자의 검색 의도를 더욱 정밀하게 파악하고 있습니다. 문장의 전체 문맥을 이해하기 때문에 불완전하거나 구어체로 작성된 검색어에도 더 정확한 결과를 제공합니다.
🤖 2. 챗봇 및 AI 어시스턴트
Transformer 기반 모델은 대화의 흐름을 이해하고 자연스러운 응답을 생성하는 데 뛰어납니다. GPT 기반 챗봇은 고객센터, 교육, 일상 대화 등 다양한 분야에서 활용되고 있습니다.
🏥 3. 의료 및 법률 문서 분석
Transformer는 방대한 문서 데이터를 빠르게 분석하고, 핵심 정보를 추출하는 데 탁월합니다. 의료 기록에서 질병 및 약물 정보를 추출하거나, 법률 문서에서 계약 조건을 요약하는 등의 작업에 사용됩니다.
📚 4. 기계 번역 및 언어 모델링
Transformer는 다양한 언어 쌍에 대해 높은 정확도의 번역 결과를 생성할 수 있으며, 다국어 모델로 확장 가능해 글로벌 서비스에 효과적으로 활용됩니다.
⚠️ Transformer의 한계와 극복 방안
💻 높은 연산 자원 요구
Transformer는 많은 파라미터를 가진 모델이기 때문에 GPU, TPU 등 고성능 하드웨어가 필요합니다. 이를 극복하기 위해 경량화된 모델(DistilBERT, TinyBERT 등)이 개발되었습니다.
🧠 데이터 편향 문제
학습에 사용된 데이터가 편향되어 있다면, Transformer 역시 편향된 출력을 생성할 수 있습니다. 윤리적인 측면에서 데이터 정제 및 검증 과정이 중요해졌습니다.
🔚 결론: 미래를 이끄는 Transformer
Transformer 모델은 인공지능의 패러다임을 바꾼 혁신적인 기술입니다. 순차적 구조의 한계를 뛰어넘어 대규모 병렬 학습을 가능케 하며, 자연어 처리뿐 아니라 컴퓨터 비전, 생물정보학 등 다방면에서 활약 중입니다.
앞으로도 Transformer를 기반으로 한 다양한 모델과 응용 기술들이 개발되며, AI 기술 발전의 핵심 동력으로 작용할 것입니다. 딥러닝을 공부하거나 AI 서비스를 개발하고자 한다면 Transformer의 원리를 제대로 이해하는 것이 필수적인 시작점이 됩니다.